[pandas] 데이터 프레임 (DataFrame)과 이어집니다
사용 데이터 : http://bit.ly/ds-korean-idol
데이터 복사
DataFrame 을 복사하려면 new = df.copy( )로 복사 해야 한다.
만일 new = df 형식으로 복사하게 된다면 메모리 주소를 둘이 같이 참조하게 되기 때문에
하나라도 데이터 값이 달라지면 나머지 DataFrame도 데이터 값이 달라진다.
new_df = df
hex(id(new_df)) # 새 데이터
hex(id(df)) # 기존 데이터
그렇다면 .copy( )를 사용해보자
new_df = df.copy()
print(hex(id(new_df)))
print(hex(id(df)))
피벗 테이블 (pivot_table)
피벗 테이블은 엑셀의피벗테이블과 동일하다.
데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회한다.
pd.pivot_table ( df , index = '행' , columns = '열' , values = '피벗 테이블 값' )
# 행 # 열 # 피벗 테이블 값
pd.pivot_table(df, index='소속사', columns='혈액형', values='키')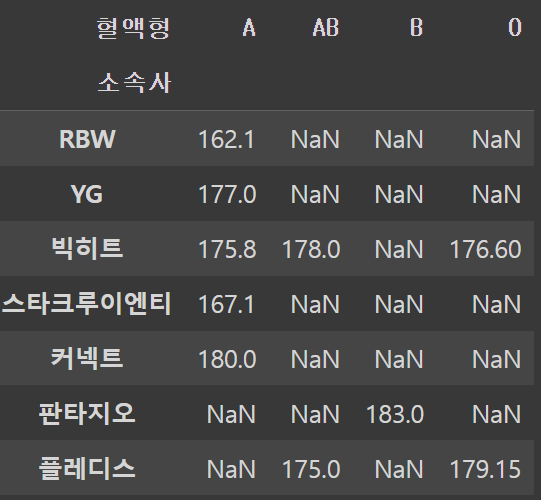
각 행과 열에 해당하는 튜플이 없을 경우 NaN가 뜬다.
GroupBy
groupby는 데이터를 그룹별로 분활하여 독립된 그룹에 대하여 별도로 데이터 처리(혹은 적용)하거나
그룹별 통계량을 확인할 때 활용한다.

Split : 컬럼 조건에 따라 독립된 그룹으로 나눈다.
Apply : 나누어진 독립된 그룹에 함수를 적용한다... 튜플은 하나가 된다.
Combine : 함수가 적용된 결과를 종합하여 다시 하나의 테이블로 합친다.
groupby와 사용
.groupby('열') .분석
min( ) : 최소값 mean( ) : 평균 count( ) 갯수
max( ) : 최대값 var( ) : 분산
sum( ) : 합계 std( ) : 표준 편차
# 1단계 # 2단계
df.groupby(['소속사', '혈액형']).mean()
[ , ] 로 지정할 그룹을 2단계로 만들 수 있다.
만일 groupby의 값을 저장을 하고 싶으면 df_group = df.groupby( ) 로 저장해야한다.
reset_index( )
위처럼 group을 만들면 인덱스 번호가 없어진다.
이 문제를 해결해 주는 것이 reset_index( ) 함수이다. (인덱스 번호가 없을 시에 .loc 함수....등 제약되는 것이 있다)
위 groupby를 df_group 변수에 저장했다고 치자
df_gorup.reset_index(inplace=True)
'Python > Pandas' 카테고리의 다른 글
| [pandas] 데이터 전처리 (0) | 2023.03.20 |
|---|---|
| [pandas] 데이터프레임 (DataFrame) (0) | 2023.03.13 |