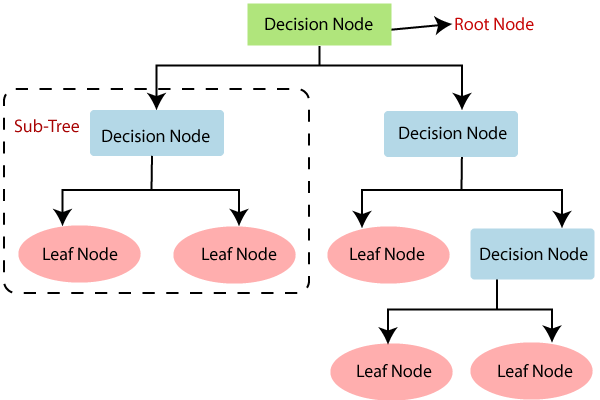
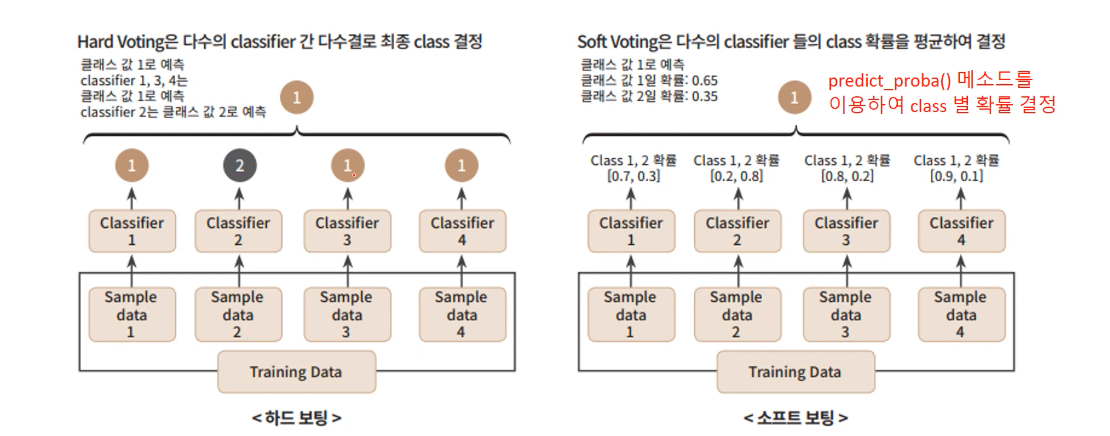
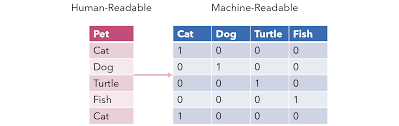
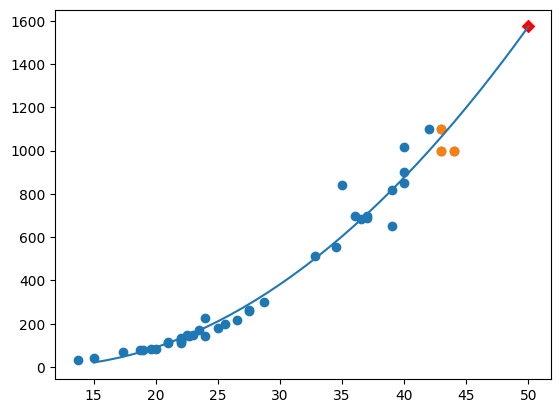
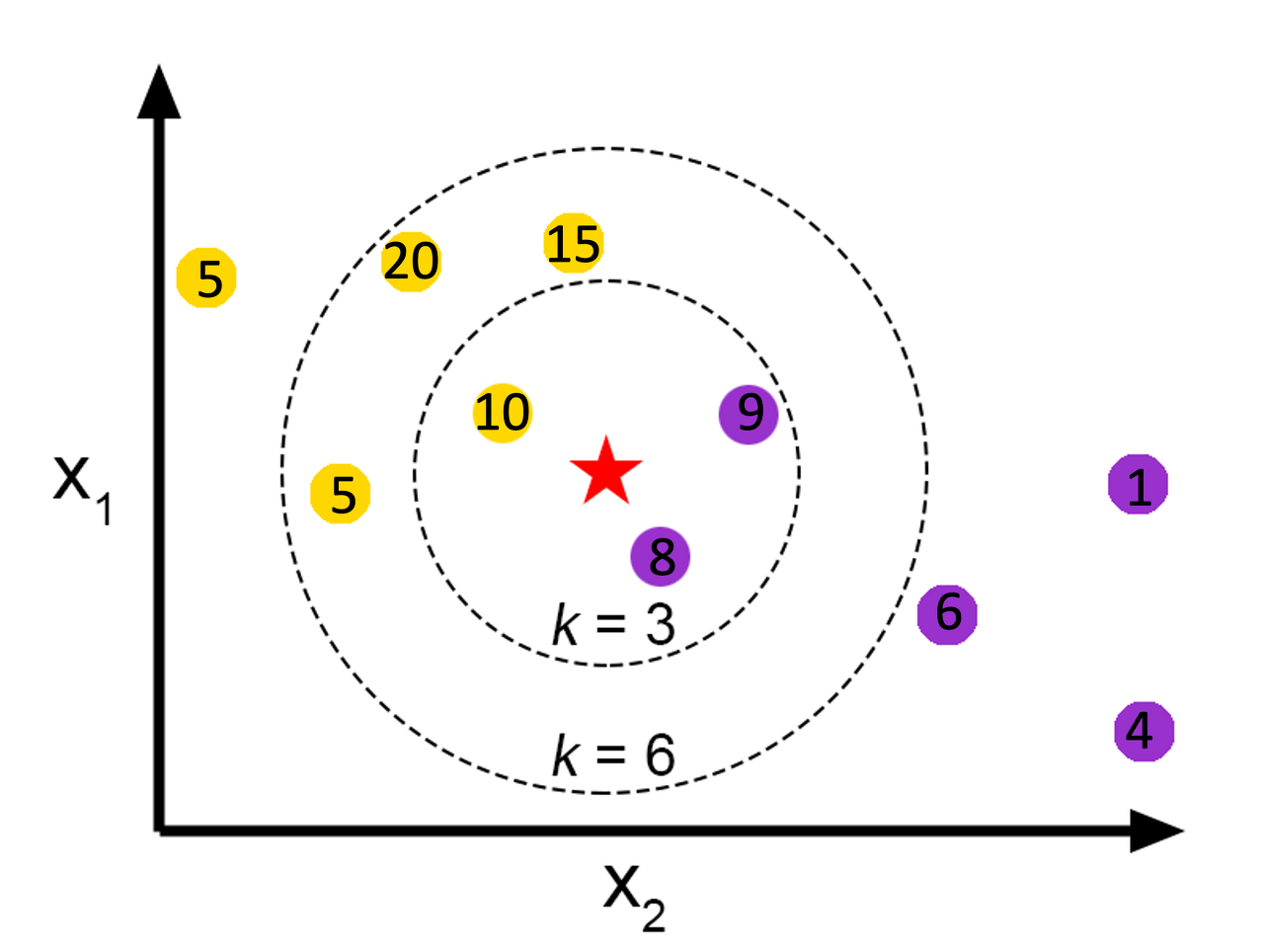
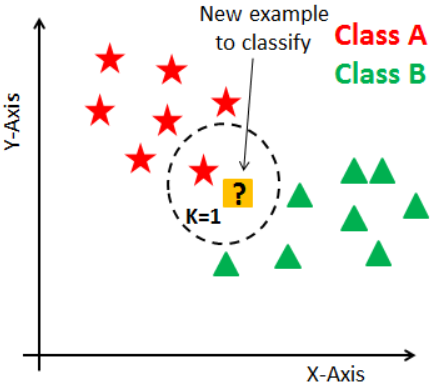
앙승블 학습을 읽고 와주세요 해당 내용에 나오는 사진과 내용은 meanxai - 에이다부스트[1/4] (Adaptive Boosting: AdaBoost) - 기본 알고리즘 에서 사용했습니다. 부스팅은 개별 트리의 실수(오차)를 통해 학습합니다. 이전 트리의 오차를 기반으로 새로운 트리를 훈련하는 것이 기본적인 아이디어입니다. (각각의 트리가 독립된 연산을 수행하는 '배깅'과 다르다는 것을 알 수 있습니다) 그 예로 에이다부스트가 있습니다. 에이다부스트는 전형적인 부스팅 학습의 일종으로써 오류 샘플의 가중치를 높여 잘못된 예측에 더 많은 주의를 기울입니다. 에이다부스트의 학습 과정 - 균등분포로 학습 데이터를 샘플링해서 weak learner (약한 모델)로 학습 후, error (추정오차)를 측정합니다..