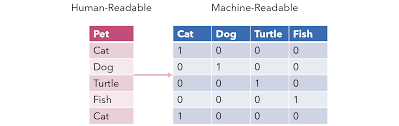
전처리는 데이터 분석에 적합하게 데이터를 가공, 변형, 처리, 클리닝하는 과정입니다. 데이터가 깔끔하지 않으면 그만큼 이를 처리하는 모델의 성능이 좋지 못한 경우가 많습니다. 그렇기에 머신러닝 학습 전에 전처리를 해야 합니다. 실제로 분석가의 80% 시간을 데이터 수집 및 전처리에 사용하고 있습니다. [pandas] 데이터 전처리 를 학습하고 오시기 바랍니다. 사용 데이터 (타이타닉) 결측치 NULL 데이터에서 .isnull( ) 또는 .isna( ) 함수를 사용해 쉽게 결측값을 찾을 수 있습니다. 만일 결측값의 갯수를 구하려면 .isna( ).sum( ) 을 사용하면 됩니다. 또한 dataFrame['칼럼명'].isnull( ) 을 하게 되면 해당 칼럼 값들만 찾을 수 있습니다. 이렇게 찾은 결측값은 ..