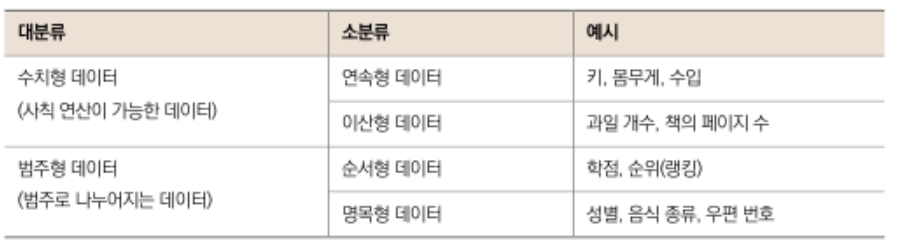
정형 데이터는 크게 수치형 데이터와 범주형 데이터로 나뉩니다.
수치형 데이터는 사칙 연산이 가능한 데이터입니다. 범주형 데이터는 사칙 연산이 불가능합니다.
이러한 수치형 데이터를 시각화를 하여 데이터의 구성 및 피처 관리를 효율적으로 할 수 있습니다.
matplotlib(맷플롯립)과 seaborn(시본) 모두 파이썬으로 그래프를 그릴때 많이 사용하는 라이브러리입니다.
그러나 이 포스트는 seaborn으로 예제를 풀겠습니다 (더 간결하고 정결합니다)
import seaborn as sns
titanic = sns.load_dataset('titanic') # 타이타닉 데이터 불러오기seaborn은 load_dataset( ) 함수로 특정 데이터셋을 쉽게 불러올수 있습니다.
titanic 데이터셋을 분석해 보겠습니다.
수치형 데이터
연속형 데이터는 값이 연속된 데이터입니다. 예를 들어 '키'는 170cm와 171cm 사이에 170.1cm 170.9999cm 등 무한히 많은 값이 있습니다. 이렇듯 값이 끊기지 않고 연속된 데이터입니다.
이산형 데이터는 정수로 딱 떨어져 셀수 있는 데이터입니다. 예를 들어 사과 개수는 3개, 4개로 딱 떨어집니다. 책의 페이지도 100페이지, 200페이지로 딱 떨어지고 200.5 페이지는 없습니다.
수치형 데이터는 일정한 범위 내에서 어떻게 분포(distribution) 되어 있는지가 중요합니다.
고르게 퍼져있을 수도, 특정 영역에 몰려 있을 수도 있습니다.
이 분포를 알아야 데이터를 어떻게 활용할지 판단할 수 있습니다.
| seaborn 제공 주요 분포도 함수 | |
| histplot( ) | 히스토그램 |
| kdeplot( ) | 커널 밀도 추정 |
| displot( ) | 분포도 |
| rugplot( ) | 러그플롯 |
히스토그램( histplot )
히스토그램은 수치형 데이터의 구간별 빈도수(값 각각의 갯수)를 나타내는 그래프입니다.
sns.histplot(data=titanic, x='age')
그래프의 x 축을 나이(age)로 잡아 각 나이의 갯수, 즉 나이별 인원수가 출력됩니다.
히스토그램을 보내 구간이 총 20개(기본값) 입니다. 이를 바꿔보겠습니다.
bins (구간 나누기)
bins 파라미터는 그래프의 구간을 나눠줍니다.
sns.histplot(data=titanic, x='age', bins = 3) # 구간을 3개로 설정
전체를 3등분 해서 count(갯수) 값을 보면 28~52 정도의 나이대의 사람들이 배에 제일 많이 탓습니다.
그럼 이제 여기서 생존한 사람들을 확인해보겠습니다.
hue (범주 적용)
hue 파라미터는 특정 범주별로 구분해서 확인할때 사용합니다.
sns.histplot(data=titanic, x='age', hue='alive') # 생존 여부 범주 적용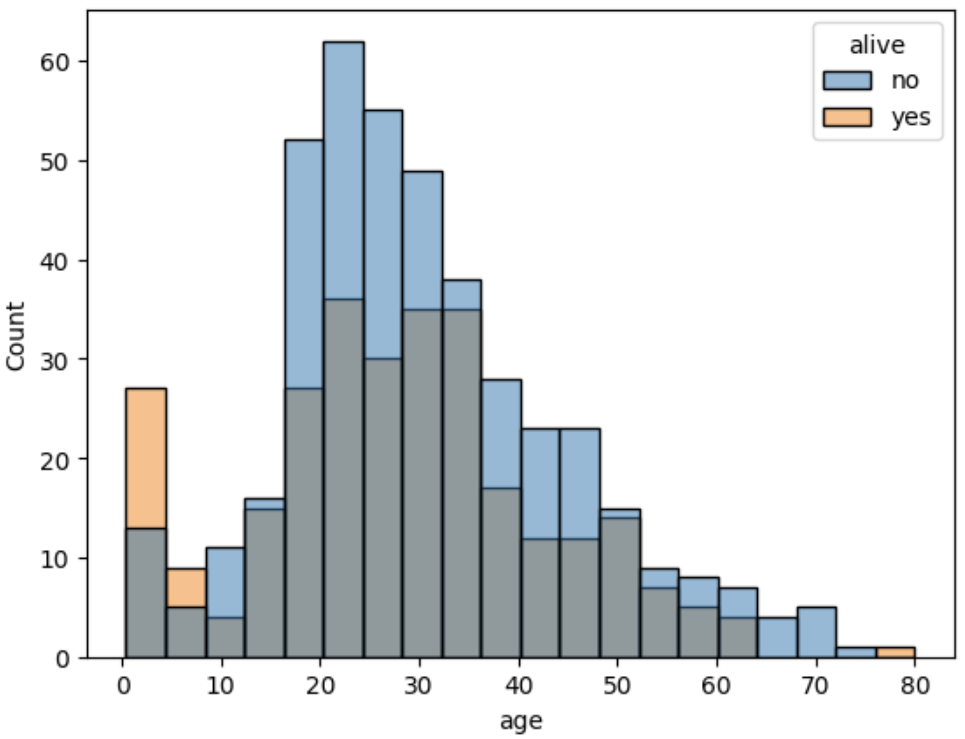
생존한 사람은 주황색, 죽은 사람은 파란색으로 표현됐습니다. 그러나
두 특성(생존 여부) 이 적용된 그래프는 서로 겹쳐서 출력됐기에, 정확한 판별이 어렵습니다.
이럴 때 multiple 파라미터를 사용합니다.
sns.histplot(data=titanic, x='age', hue='alive', multiple='stack')
커널밀도추정( kdeplot )
커널밀도추정은 쉽게 생각해 히스토그램을 매끄럽게 곡선으로 연결한 그래프로 이해하면 됩니다.
sns.kdeplot(data=titanic, x='age', hue='alive', multiple='stack')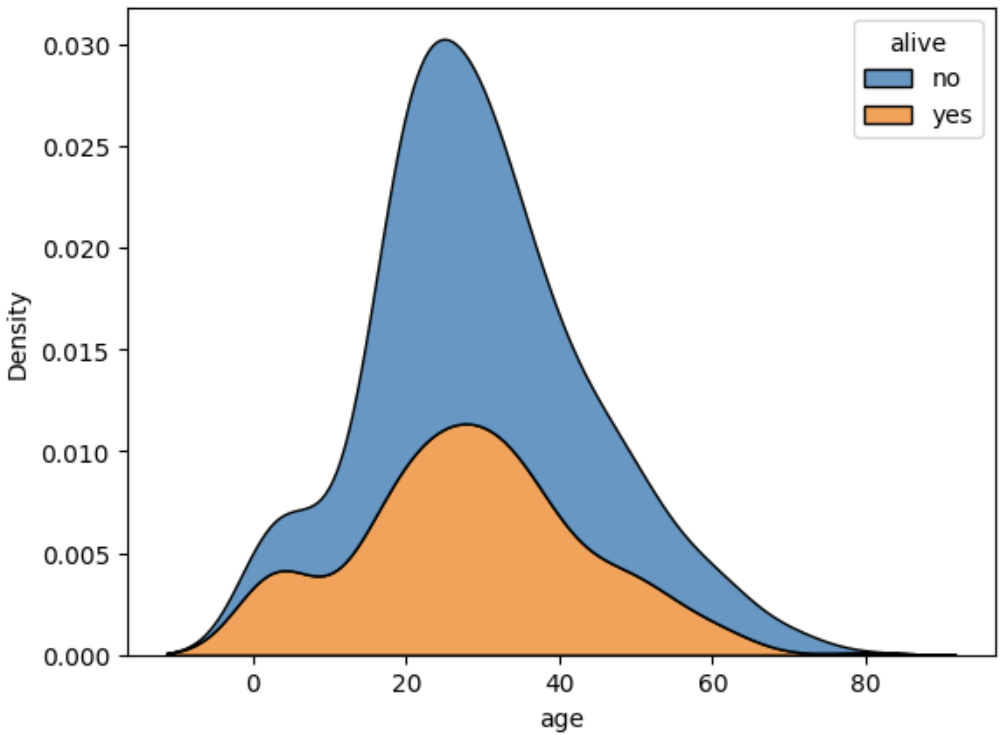
앞서 본 누적 히스토그램과 비교하면 이산적인지 연속적인지 차이가 있을 뿐이지 전체적인 모양은 같습니다.
이산적 = 값이 정수로 딱 떨어짐, 연속적 = 값이 실수 처럼 무한적으로 많음
분포도( displot )
분포도는 수치형 데이터 하나의 분포를 나타내는 그래프입니다.
캐글에서 분포도를그릴 땐 displot( )을 많이 사용합니다. 파라미터만 조정하면 histplot( )과 kdeplot( )이 제공하는 기본 그래프를 모두 그릴 수 있기 때문입니다.
sns.displot(data=titanic, x='age', kind='hist') # 히스토그램
sns.displot(data=titanic, x='age', kind='kde') # 커널밀도추정
sns.displot(data=titanic, x='age', kde=True) # 두개 다!!!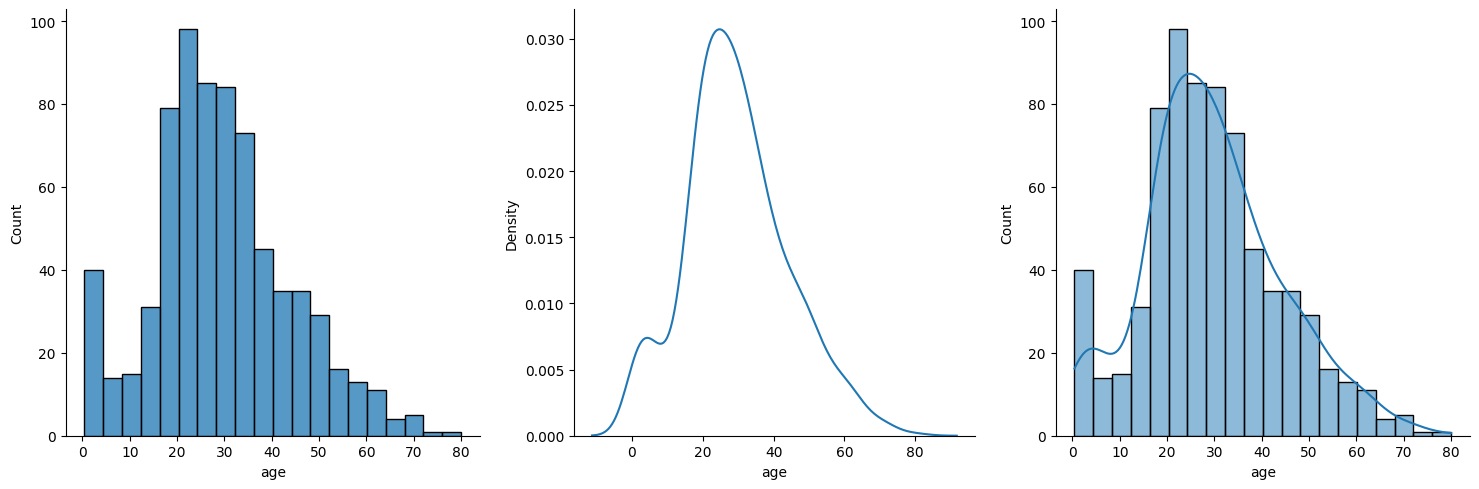
러그플롯( rugplot )
러그플롯은 주변 분포를 나타내는 그래프입니다. 단독으로 사용하기보다는 주로 다른 분포도와 함께 사용합니다.
sns.kdeplot(data=titanic, x='age')
sns.rugplot(data=titanic, x='age') # 피처의 분포도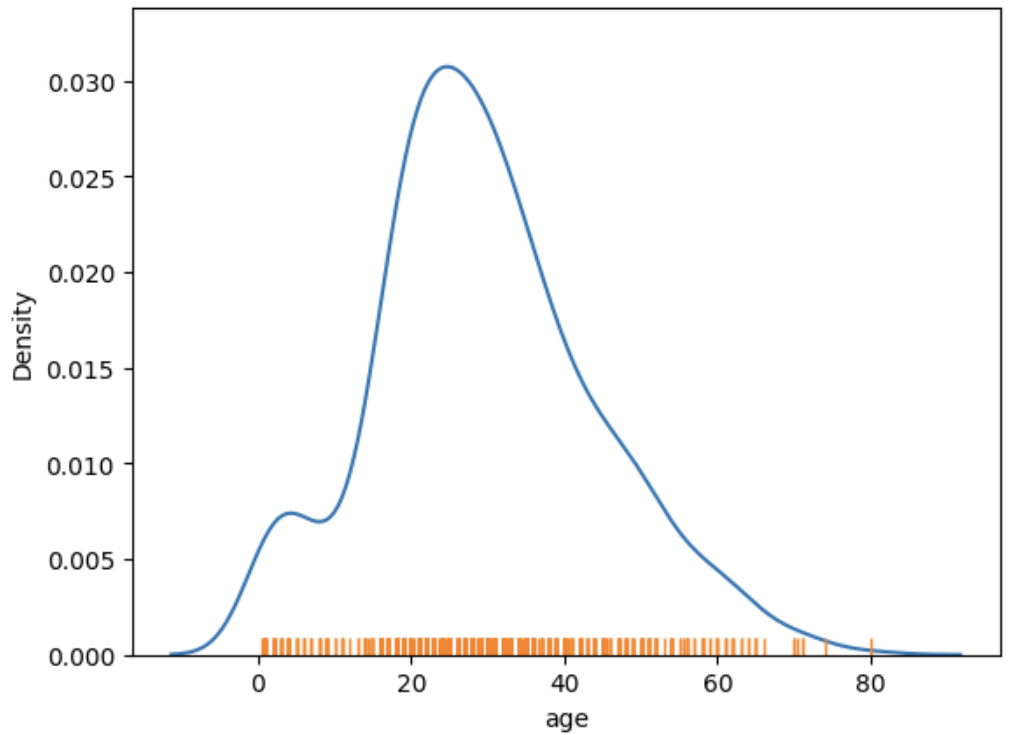
러그플롯은 단일 피처(여기서는 age 피처)가 어떻게 분포돼 있는지를 x축 위에 작은 선분(러그)로 표시합니다.
값이 밀집돼있을수록 작은 선분들도 밀집돼 있습니다.
'Python > 기타' 카테고리의 다른 글
| [seaborn 시본(2)] 데이터 시각화 - 범주 데이터 (0) | 2023.04.30 |
|---|