앙상블(Ensemble)
여러 분류기(Classifier)를 하나의 메타 분류기로 연결하여 개별 분류기보다 더 좋은 성능을 달성하는 학습법입니다
쉽게 말해 '집단 지성'과 같이 강력한 하나의 모델을 사용하는 대신보다 약한 모델 여러 개를 조합하여 더 정확한 예측을 합니다.
하나의 모델이 학습 데이터에 과적합(overfitting) 되는 것을 막기 위해 약한 모델을 여러 개 결합시켜 그 결과를 종합한다는 게 기본적인 앙상블의 아이디어입니다
앙상블 학습 방법
앙상블 학습은 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 스태킹(Stacking)이 있습니다.
보팅(Voting)
보팅은 서로 다른 알고리즘 모델 여러 개를 결합하여 구해진 예측값들을 투표를 통해 결정하는 방식입니다.
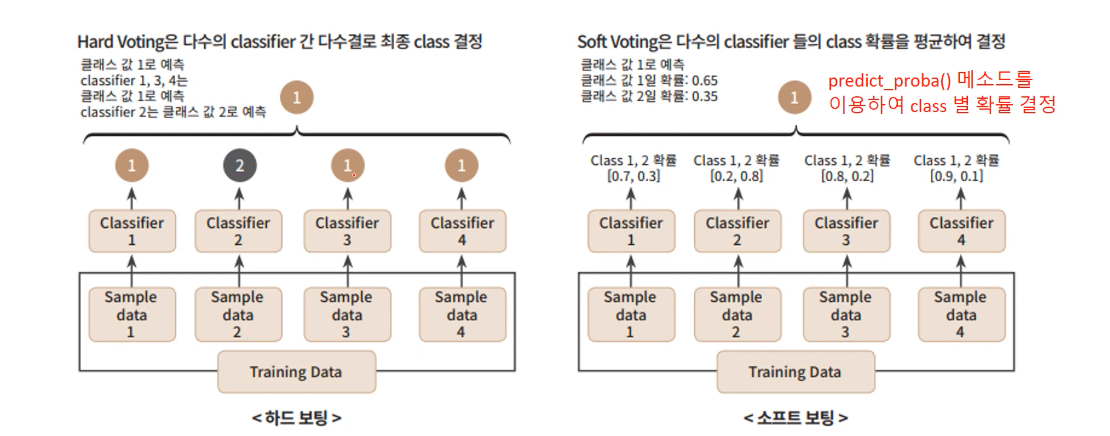
보팅은 하드 보팅과 소프트 보팅으로 나뉩니다.
- 하드 보팅 (Hard Voting): 다수의 분류기가 예측한 결과값을 최종 결과로 선정 [다수결의 원칙과 유사]
- 소프트 보팅 (Soft Voting) : 각 알고리즘이 예측한 레이블 값 결정 확률의 평균을 구한 뒤 가장 확률이 높은 레이블 값을 최종결과로 선정
VotingClassifier
VotingClassifier는 여러 개의 분류기를 결합하여 다수결 투표나 평균 등의 방식으로 최종 예측을 수행하는 사이킷런 제공 모델입니다
# 앙상블(보팅) 모델
from sklearn.ensemble import VotingClassifier # 보팅
# 개별 모델
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀
from sklearn.neighbors import KNeighborsClassifier # K-최근접 이웃# 개별 분류기 생성
lr_clf = LogisticRegression(solver='liblinear')
knn_clf = KNeighborsClassifier(n_neighbors = 5)
# 앙상블(보팅) 생성
vo_clf = VotingClassifier( estimators = [ ('LR', lr_clf), ('KNN', knn_clf) ],
voting = 'soft' # 보팅 방식 선택
) # 하드 보팅 : 'hard' 소프트 보팅 : 'soft'estimators 매개변수는 분류기를 리스트로 추가하고, 각 분류기에 이름을 지정합니다
voting 배개변수는 보팅 방식을 설정하며 hard는 다수결 투표(하드 보팅), soft는 확률의 평균(소프트 보팅)을 사용합니다.
배깅 (Bagging : Bootstrap Aggregation)
배깅은 각각의 샘플(Bootstrap)을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계하는 방법입니다.
보팅과 다르게 각 분류기는 모두 같은 유형의 알고리즘을 사용합니다

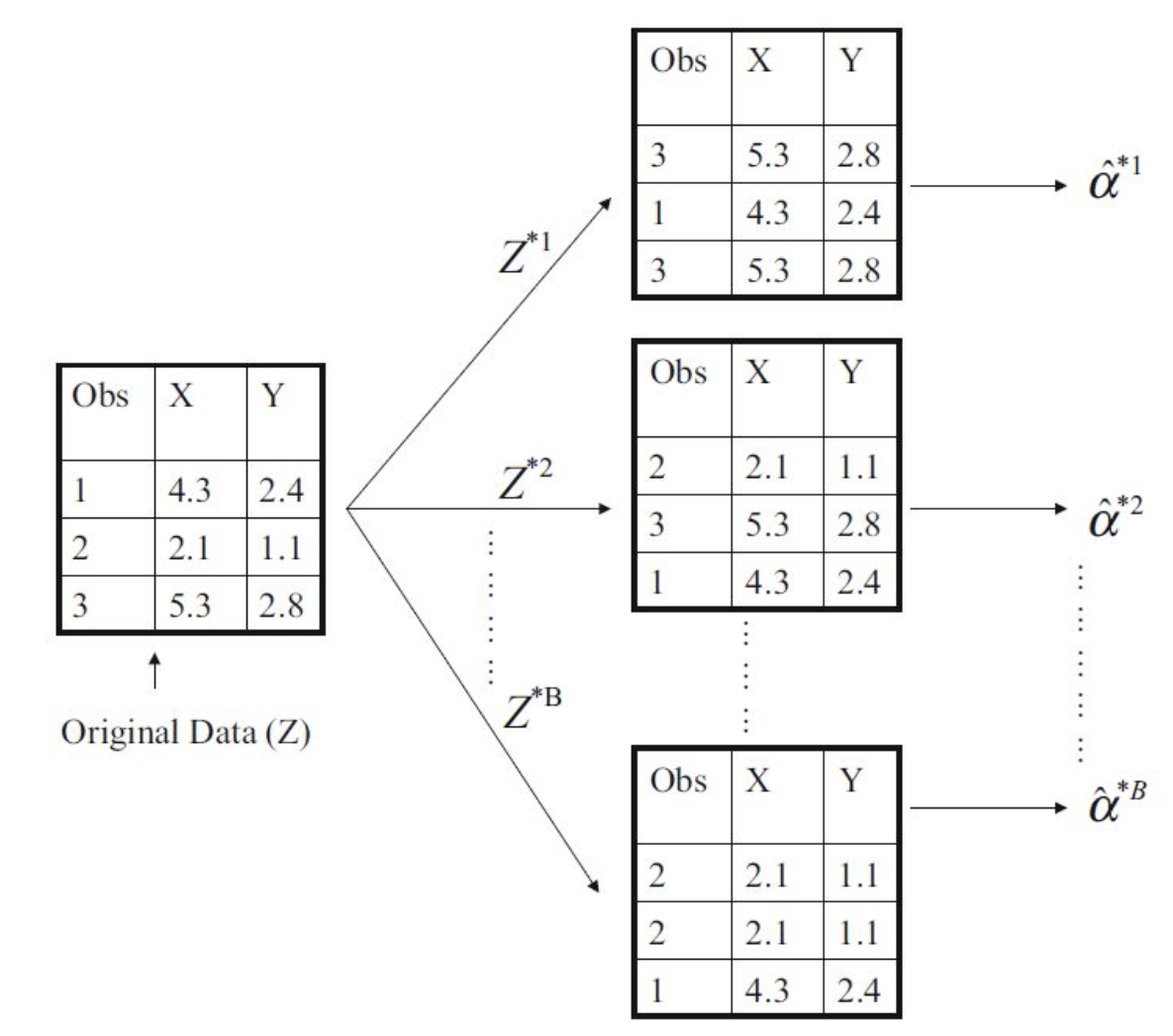
부트스트랩 추출법(Bootstrap Sampling)
부트스트랩은 복원추출을 통해 원래 데이터의 수만큼 크기를 같도록 하는 샘플링 방법으로,
하나 모델에 대하여 데이터 추출을 할 경우 중복된 데이터가 있을 수 있습니다.
아래 그림은 N = 3인 Original data로 N번의 복원 추출을 각각 시행하여 총 B개의 부트스트랩 데이터 셋을 생성했습니다.
BaggingClassifier
BaggingClassifier는 배깅(Bagging) 방식을 사용하여 다양한 기본 분류기를 결합하여 예측을 개선하는 사이킷런 제공 모델입니다.
# 앙상블(배깅) 모델
from sklearn.ensemble import BaggingClassifier
# 개별 모델
from sklearn.tree import DecisionTreeClassifier# 개별 모델 생성
dtc = DecisionTreeClassifier()
bg_clf = BaggingClassifier(
dtc, # 기본 분류기 지정
n_estimators = 100, # 생성할 분류기 개수
max_samples = 0.5, # 분류기에 들어갈 샘플의 비율
bootstrap = True, # 부트스트랩 사용 여부
n_jobs = 1 # 사용할 컴퓨터 코어 수
)기본 분류기로 (DecisionTreeClassifier)를 사용했습니다
n_estimators 매개변수는 생성할 분류기의 개수
max_samples 매개변수는 각 분류기가 사용할 샘플의 비율
max_features 매개면수로 특성 샘플링 비율을 설정할 수 있습니다.
부스팅 (Boosting)
부스팅은 여러개의 약한 학습기(weak learner)를 순차적으로 학습 및 예측을 하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선하는 학습 방식입니다.부스팅은 예측력이 약한 모형들을 결합하여 강한 예측 모형을 만들기 때문에 훈련 오차를 빠르고 쉽게 줄일 수 있다는 장점이 있습니다
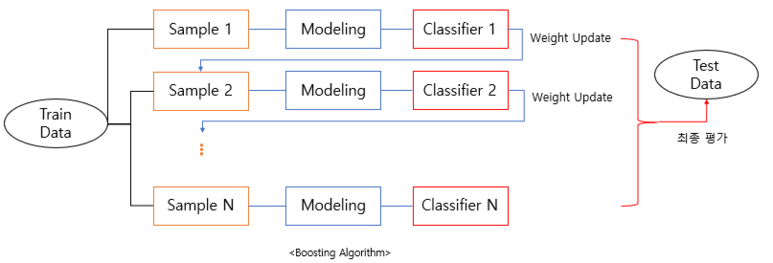
부스팅은 각각의 약한 모델(weak learner)이 하나의 데이터 셋을 순차적으로 학습합니다.
샘플 1에서 잘 분류하지 못한 데이터에 가중치를 주고 샘플 2로 넘겨줍니다.
(랜덤 샘플링이기 때문에 샘플 2에는 샘플 1에 포함하지 않는 데이터도 있습니다)
AdaBoostClassifier
AdaBoostClassifier는 사이킷런에서 제공하는 에이다부스트(AdaBoost) 알고리즘을 사용하는 분류 모델입니다.
에이다부스트는 학습에 이용된 개별 분류기에 서로 다른 가중치를 주어서 최종 분류기를 만들어 냅니다.
# 앙상블(부스팅) 모델
from sklearn.ensemble import AdaBoostClassifier
# 개별 모델
from sklearn.tree import DecisionTreeClassifier# 기본 분류기 생성
base_classifier = DecisionTreeClassifier(max_depth=1) # 약한 학습기 생성
# 에이다부스트 생성
adb_clf = AdaBoostClassifier(
base_classifier, # 기본 분류기
n_estimators=50, # 약한 학습기 개수
learning_rate=1.0, # 학습률 (기본값)
)learning_rage 매개변수는 학습률을 설정합니다. 학습률은 각 모델의 가중치 업데이트 정도를 조절하기 때문에
값이 작을수록 학습이 느리고 안정적이며, 값이 클수록 학습이 빠르고 불안정합니다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 앙상블 - 에이다부스트 (AdaBoost) (0) | 2023.09.27 |
|---|---|
| [머신러닝] 결정트리 (Decision tree) (0) | 2023.09.22 |
| [머신러닝] 전처리 (pre-processing) (1) | 2023.04.11 |
| [머신러닝] 회귀(Regression) 선 그래프 (1) | 2023.04.08 |
| [머신러닝] K - 최근접 이웃 회귀 (K-NN Regression) 01 (0) | 2023.04.08 |